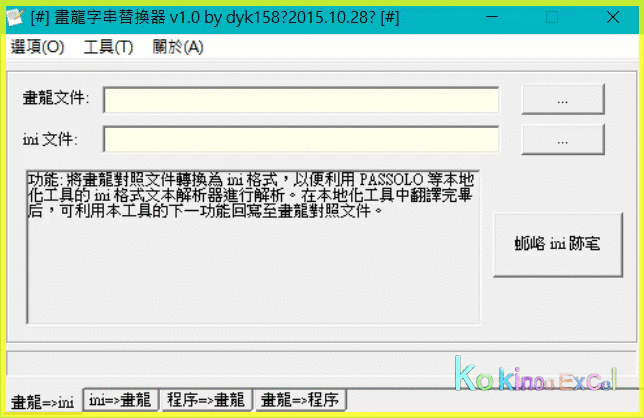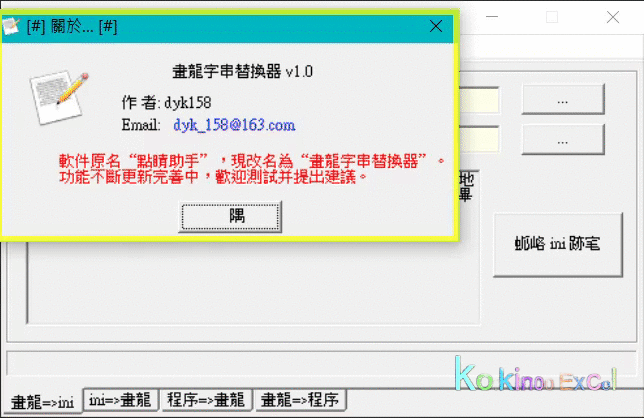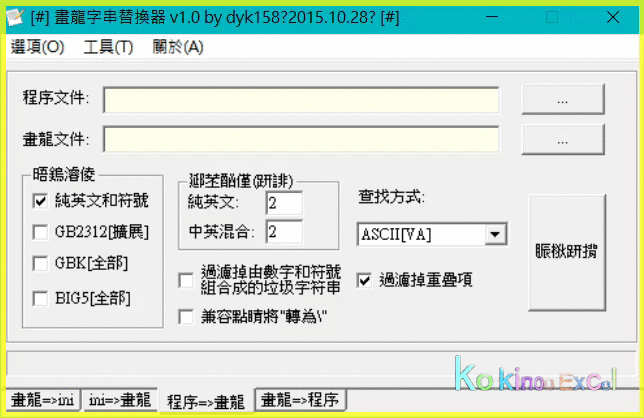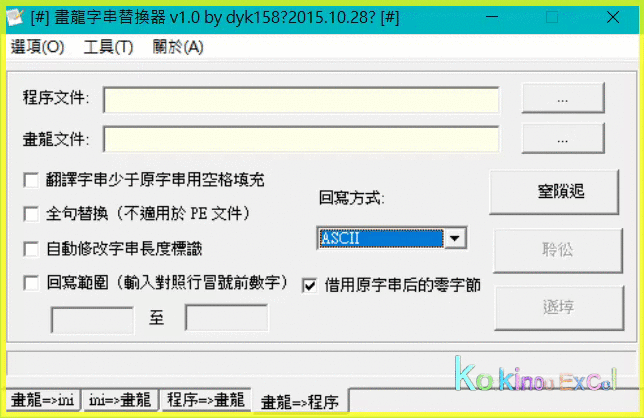
iii 若有Error字串,須處理掉,才能進行Step3
iv [Step3 設定刪除>= 重複值]按鈕,搭配遞減排序,邊檢查邊設定刪除重複次數大的程式碼字串;字串長度遞減排序,剪下正常字串
v [正規表示式]下拉式選單是簡單的條件;複雜條件請自行手key輸入(結果可框選刪除或剪下至Final工作表G欄位)。正規式是針對iv挑剩下字數少但數量龐大,無規律的字串做篩選
◊搭配[剪下ToFinal]按鈕,框選要的字串,自動剪下貼到Final工作表G欄位,並清除空白列上移
vi [Final工作表]將您篩選完的字串列(Step1工作表G欄位)與原始AB欄字串核對,還原產生 (上)ID+(下)字串 {單欄結果}